Table of Contents
- Introduction
- Migration Strategy: Parallel Architecture
- Understanding the Architecture
- Technical Challenges
- Implementation Details
- Lessons Learned
- Conclusion
- References:
Introduction
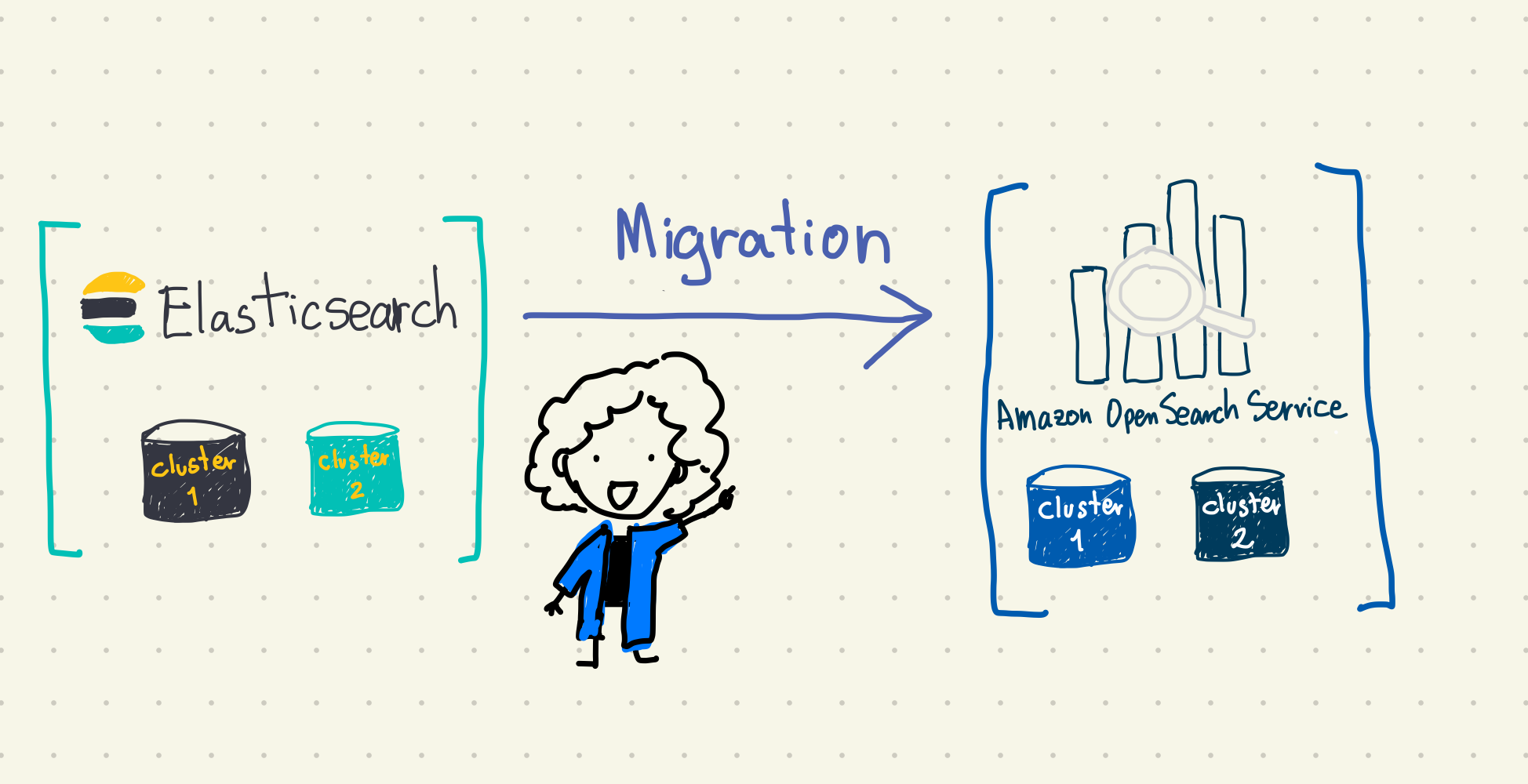
At the beginning of this year, I was focused on migrating a long-running service from ElasticSearch to Amazon OpenSearch Service.
This service has existed for many years and uses two ElasticSearch clusters as part of its architecture—one that contains raw data received from queues and the other with the indexed data. The cluster with raw data has a set of 4 data nodes (m5.xlarge.search - non Graviton instance) and the search cluster with 7 data nodes (c6g.8xlarge.search - already using Graviton instance). There are also two environments, production and sandbox. The sandbox mirrors production but with fewer resources, less nodes and small instances.
Over time, there were some attempts to migrate to Graviton instances for improved performance and cost efficiency. Unfortunately, those attempts led to incidents that required rollbacks, only on the search cluster. One of them was related to the metric JVMMemoryPressure which was only monitoring the old generation of the Java heap, leading to inaccurate reflection of memory usage.
After learning that Amazon OpenSearch Service has improved the logic used to calculate JVM memory usage, the team decided to give it another shot.
Migration Strategy: Parallel Architecture
Our goal was to avoid any downtime and to achieve that, we would duplicate the entire architecture and run it in parallel and properly monitor things like index rate, CPU utilization, storage space, JVMMemoryPressure and costs.
This would allow us to test everything and switch seamlessly once we’re confident with the new setup. The switch would happen by changing the DNS alias to point to the new service. After that, and some time monitoring we would delete the unnecessary resources.
Understanding the Architecture
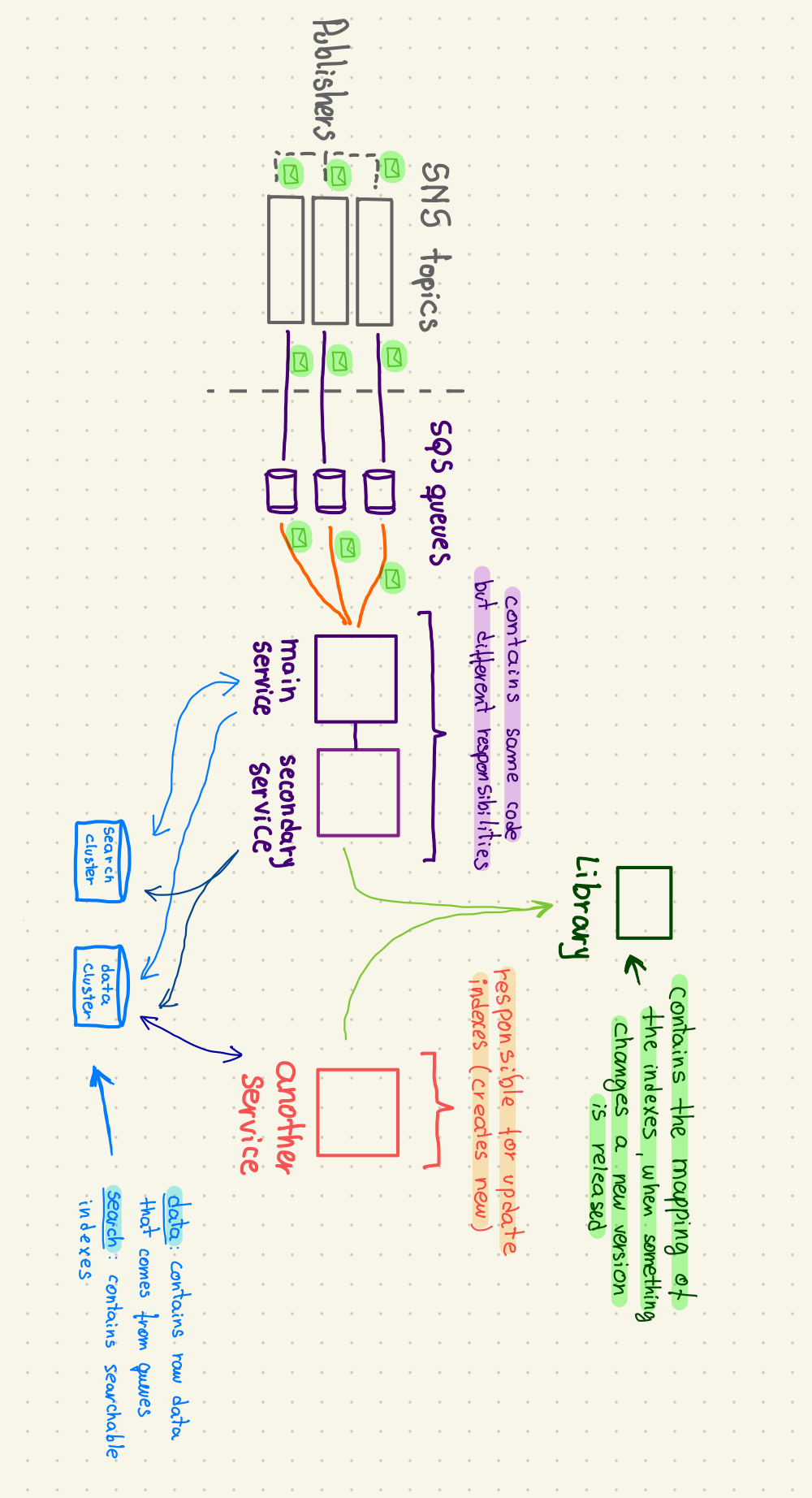
Understanding the existing architecture was a challenge in itself. The infrastructure is complex, involving services, libraries, SQS queues, SNS topics, permissions and the deployment strategy.
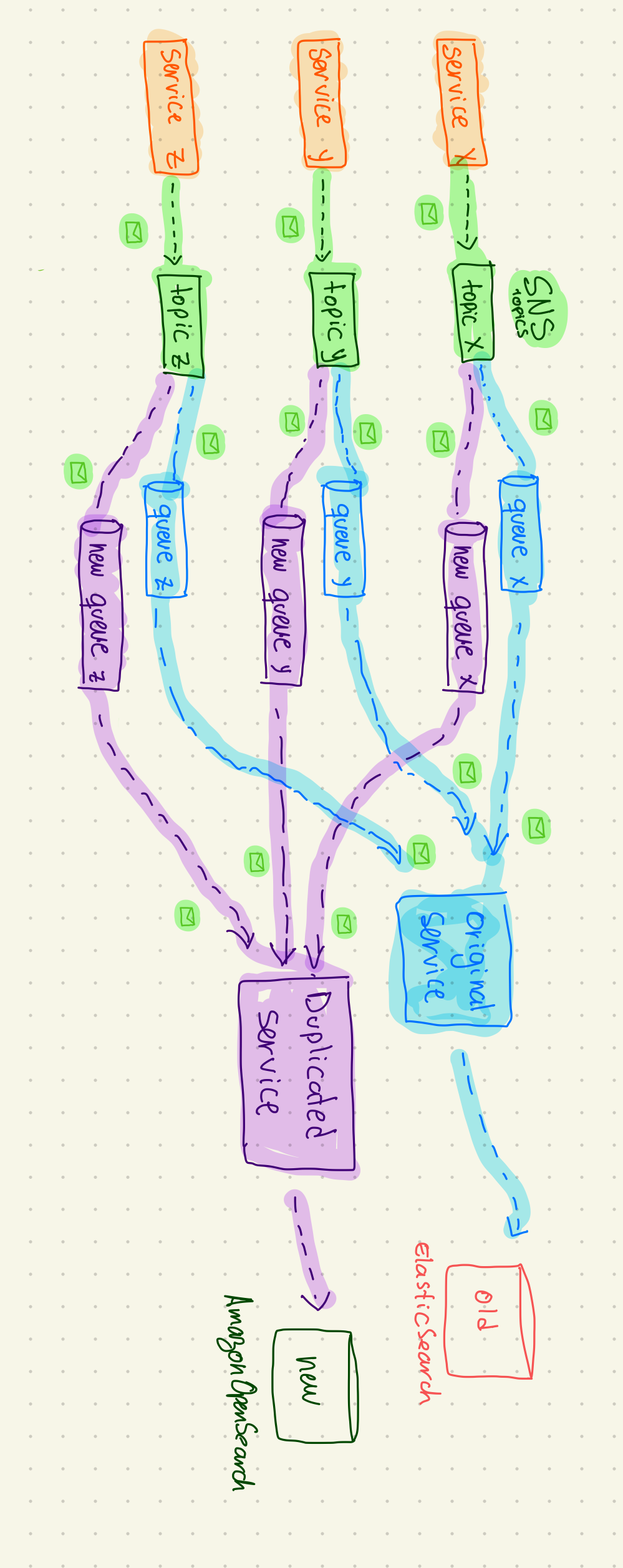
To prevent message loss, we duplicated the entire set of queues and subscribed them to the same SNS topic. This way, both the old and new services (cloned) could receive the same data:
- The old queues connected to the existing service writing to ElasticSearch
- The new queues connected to the new service writing to OpenSearch
We also faced IAM-related constraints. The duplicated services couldn’t use the same IAM roles as the originals. So, we needed to ensure the new IAM roles had the correct permissions and adding it to some allowlist from another service not managed by us.
Technical Challenges
- Data type limitation
Before even start on sandbox, we made a POC with an OpenSearch cluster, which we attempted to restore a snapshot and recreate indexes. One issue we faced involved a field of type geo_shape, the error was: DocValuesField appears more than once in this document (only one value is allowed per field . We had to set doc_values: false to avoid errors when indexing this data.
I was not aware of this field and this property at all, therefore I felt I needed to understand deeper what that meant and how it works. As I learned, this doc_values is enabled by default which enables operations like sorting and aggregation, and it’s stored on disk. This geo_shape field was storing multiple values like an array of polygons. We decided to disable doc_values for this specific field, as we also don’t use it for any sorting or aggregation.
- Deployment Pressure
We had to be cautious with deployments, especially on Fridays. We wanted enough time to monitor the behavior of some sort of change.
Everything had to be executed in a streamlined process. For example, once the new queues were cloned, they had a 3-day message retention period, to restore the snapshot and start the service to get the messages that were piling up.
If the service wasn’t connected in time to process the messages and with the snapshot restored we risked losing the data we would need to create a new snapshot and start again.
We faced this exact scenario. On the final day of the retention window, messages were piling up. Fortunately, we resolved the issue and connected the service just in time.
- Rightsizing EBS Volumes
We also planned to resize the EBS volumes that are connected to the clusters. There was some investigation done some time ago by another colleague that we could reduce the volume sizes. For that we also needed to understand how that works, as we also discovered that we need to consider IOPS and throughput values depending on the type of volume like gp2 or gp3. Everything around resizing the EBS volumes also required some calculation on costs, depending on how many instances we would need. We had done a lot of calculations, because at the end it this migration should save us some costs in the future. During the migration was expected to have some more costs as we were duplicating everything.
There were of course some other technical challenges we faced, those were just some that we spend more time.
Implementation Details
The sandbox environment was key to testing the entire duplication process and planning the production rollout.
We also had to:
- Create additional environments (e.g., box-v6, pro-v6);
- Extend Spring profiles to set the correct queue and cluster URLs;
- Duplicate all the stacks needed using CloudFormation;
- Modify Jenkins pipelines to deploy and sync the new stacks;
This ensured the duplicated infrastructure like OpenSearch clusters, queues, services, and IAM role, dashboards, was properly configured and easily deployable.
Lessons Learned
Understand the architecture and dependencies before starting a migration, to have an idea how the changes could affect the running service.
Seamless switching requires careful planning to avoid data loss, therefore understanding the architecture was essential.
Communication is crucial, we had to ensure that the whole team is informed what's happening to quickly spot unexpected behavior during the day.
Pair programming and mentorship are incredibly valuable. Combining historical knowledge with fresh eyes helped us spot issues faster and make smarter decisions.
Documenting the process is important, with so many small details sometimes we got lost when we forgot how we decided to do something. Writing down details on pull requests, tickets can help tracking the process and better understand when something goes wrong.
Conclusion
Although we didn’t end up using Graviton instances, because we had already committed to reserved instances until the end of the year, we successfully migrated from ElasticSearch to Amazon OpenSearch Service. There was a minor issue we couldn't predict, related with the creation of new environments, some part of the code could not handle that, but we fixed that.
We noticed CPU performance improvement and valuable lessons for future migrations, as we will need to do the same migration when we switch to Graviton.
References:
- Understanding the JVMMemoryPressure metric changes in Amazon OpenSearch Service
- Managing Amazon EBS volume throughput limits in Amazon OpenSearch Service domains
- Amazon EBS General Purpose SSD volumes
- OpenSearch doc_values
- Geoshape field type
Well, I procrastinated writing this article for too long, but I finally managed to post it during my vacation 😅. This was a really cool initiative I worked on during the first quarter of the year. I love understanding complex architectures and getting hands-on, but I’m also very careful. I prefer spending time understanding as many things as I can, creating diagrams, documenting, to proper plan the steps needed. At the same time, I really appreciate having someone more experienced around, someone who knows the hidden details of the architecture, the kind of knowledge you only gain through experience. And this initiative has definitely become one of my favorites. :)
If you're still here. Thanks for reading :)